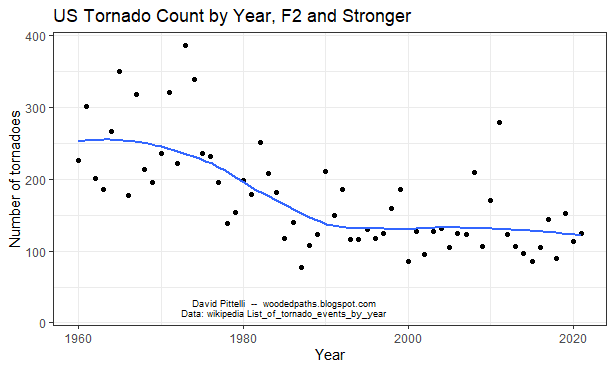
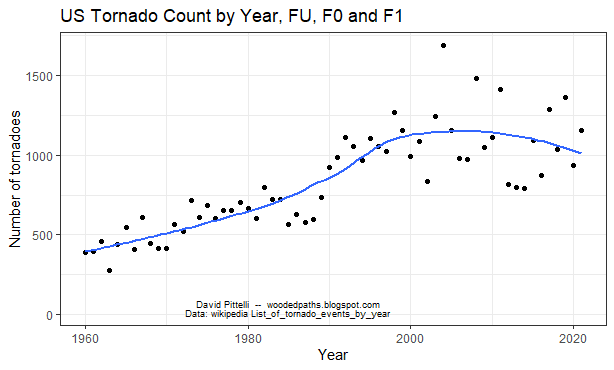
There's been a lot of debate online about how
various countries have fared in the face of the COVID-19 pandemic. Often the countries chosen are cherry-picked,
or the measure of deaths (i.e., totals, not rates) says more about the size of
the countries' populations than their success or failure in any meaningful
sense.
There are just 6 major countries with higher
reported death rates than the US. But
the fact that all of them are well-functioning economies and democracies in
Western Europe would tend to refute the notion that economic or political
backwardness is the key to their high death rates.
In my opinion, the key disadvantages that the
US and Western Europe have, relative to less wealthy countries and isolated islands
like New Zealand, is that the former are so large and interconnected (in terms
of travel). A Western, especially US,
reluctance to wear masks is also a major disadvantage relative to East Asian
countries.
To illustrate such comparisons, I've written
an R script to download the latest daily data from the European Centre for
Disease Prevention and Control (ECDC), and turn daily death rates for selected
countries into a line graph, such as here (click on graph for higher
resolution; the graph is followed by my R script).
Note that Spain has revised figures downward for
a reputed overcount of prior deaths; rather than go back and alter prior days'
numbers, they did this by logging 1,918 "negative deaths" on May
25. Later they revised numbers upward by
1,179 on June 19.
# **********************
# R Code to download and graph ECDC historical
daily data
# David Pittelli -- woodedpaths.blogspot.com
# https://www.ecdc.europa.eu/en/publications-data/download-todays-data-geographic-distribution-covid-19-cases-worldwide
setwd("C:/Users/YourDirectory")
rm(list=ls())
# Load functions************
library(ggplot2)
library(scales)
library(RColorBrewer)
# Manual color
adjust****************
ggplotColours <- 360="" function="" h="c(0," n="6," o:p="">
if ((diff(h)%%360) < 1) h[2] <- -="" 360="" h="" n="" o:p="">
hcl(h = (seq(h[1], h[2], length = n)), c =
100, l = 65)
}
# Download data from web************
df = read.csv("https://opendata.ecdc.europa.eu/covid19/casedistribution/csv",
na.strings = "", fileEncoding = "UTF-8-BOM", stringsAsFactors=FALSE)
# convert date info in format
'mm/dd/yyyy'
df$date2 =
as.Date(df$dateRep, "%d/%m/%Y")
# Subset rows and add columns
***********************
# eliminate NAs in countryterritoryCode
df =
df[!is.na(df$countryterritoryCode),]
# Add deaths per 100 Million
column
df$DPC = (df$deaths * 100000000)
/ df$popData2019
# Add cases per 100 Million
column
df$CPC = (df$cases * 100000000)
/ df$popData2019
# Add 7-day moving averages
# vectors are reversed since
MA can only look upwards (or in both directions)
df$DPCMA = rev(filter(rev(df$DPC),
rep(1/7,7), sides = 1))
df$CPCMA = rev(filter(rev(df$CPC),
rep(1/7,7), sides = 1))
df$deathsMA = rev(filter(rev(df$deaths),
rep(1/7,7), sides = 1))
# Add day of week and 1-7 *****************************
df$dayOfWeek =
weekdays(as.Date(df$date2))
df$dayNum = setNames(0:6,
c("Sunday", "Monday", "Tuesday",
"Wednesday", "Thursday", "Friday",
"Saturday"))[weekdays(as.Date(df$date2))]
# Save with a file name including today's
date***********
today = paste(substr(date(), 5, 10),
substr(date(), 21, 24))
filename = paste(today, "ECDC COVID
table.csv")
write.csv(df, filename)
# Just look since March 1
df = df[df$date2 > as.Date("2020-02-29"),
]
# Graph
***************************************
# Select Countries
df2 = df[df$geoId == "ES"
| df$geoId == "IT" | df$geoId == "UK" | df$geoId == "SE"
| df$geoId == "US" | df$geoId == "DE" | df$geoId == "KR"| df$geoId == "NZ",]
# Annotated plot, 7-day
Moving Average, linear scale
p = ggplot(data = df2, aes(x
= date2, y = DPCMA, group = geoId, color = geoId)) +
geom_line(size = 1.2) +
theme_bw() +
ggtitle(paste("Daily Death Rate from
COVID-19, 7-Day smoothing,", today)) +
theme(plot.title
= element_text(size = 24)) +
theme(axis.title.x =
element_text(size=14)) +
theme(axis.title.y =
element_text(size=14)) +
theme(axis.text.x = element_text(size=14))
+
theme(axis.text.y =
element_text(size=14)) +
theme(legend.text
= element_text(size = 14)) +
xlab("Date") + ylab("Daily Deaths
per 100 Million People") +
theme(legend.title=element_blank())
# Manual colors; black for US
p + scale_colour_manual(breaks=c("ES",
"IT", "UK", "SE", "US", "DE",
"KR", "NZ"), labels=c("Spain", "Italy",
"UK", "Sweden", "US", "Germany",
"S. Korea", "New Zealand"),
values =c(ggplotColours(7),
"black")) +
annotate("text", x = as.Date(18425,
origin="1970-01-01"), y = 1750, label="David Pittelli --
woodedpaths.blogspot.com\nData from ecdc.europa.eu", col =
"black")